Week 7 (Cont.): Arabic Speech Data
The data has arrived!
Some licensing issues related to the MGB-2 data set resulted in the data not being available for a while (I wish I will be able to work with it before the end of this summer). Luckily, my mentors contacted the Linguistic Data Consortium (LDC) hosted by the University of Pennsylvania, and we managed to obtain the GALE Phase 2 Arabic Broadcast Conversation Transcripts - Part 1 corpus (LDC2013T04), and the corresponding text, GALE Phase 2 Arabic Broadcast Conversation Transcripts Part 1 (LDC2013T04).
In this follow-up post, I’ll talk about the corpus and how we will deal with the data.
The corpus
GALE Phase 2 Arabic Broadcast Conversation Transcripts - Part 1 corpus consists of 123 hours of conversation speech from a multitude of broadcast programs from all over the Middle East. The transcripts total 752,747 tokens of Arabic text encoded in UTF-8, produced by LDC’s transcription tool, XTrans.
The data is mainly in Modern Standard Arabic (MSA). Some of the utterances contain non-MSA parts, tagged in the transcripts as “non-MSA”. Some utterances are also non-Arabic, thus non-included as empty utterances in the transcripts.
Transcripts
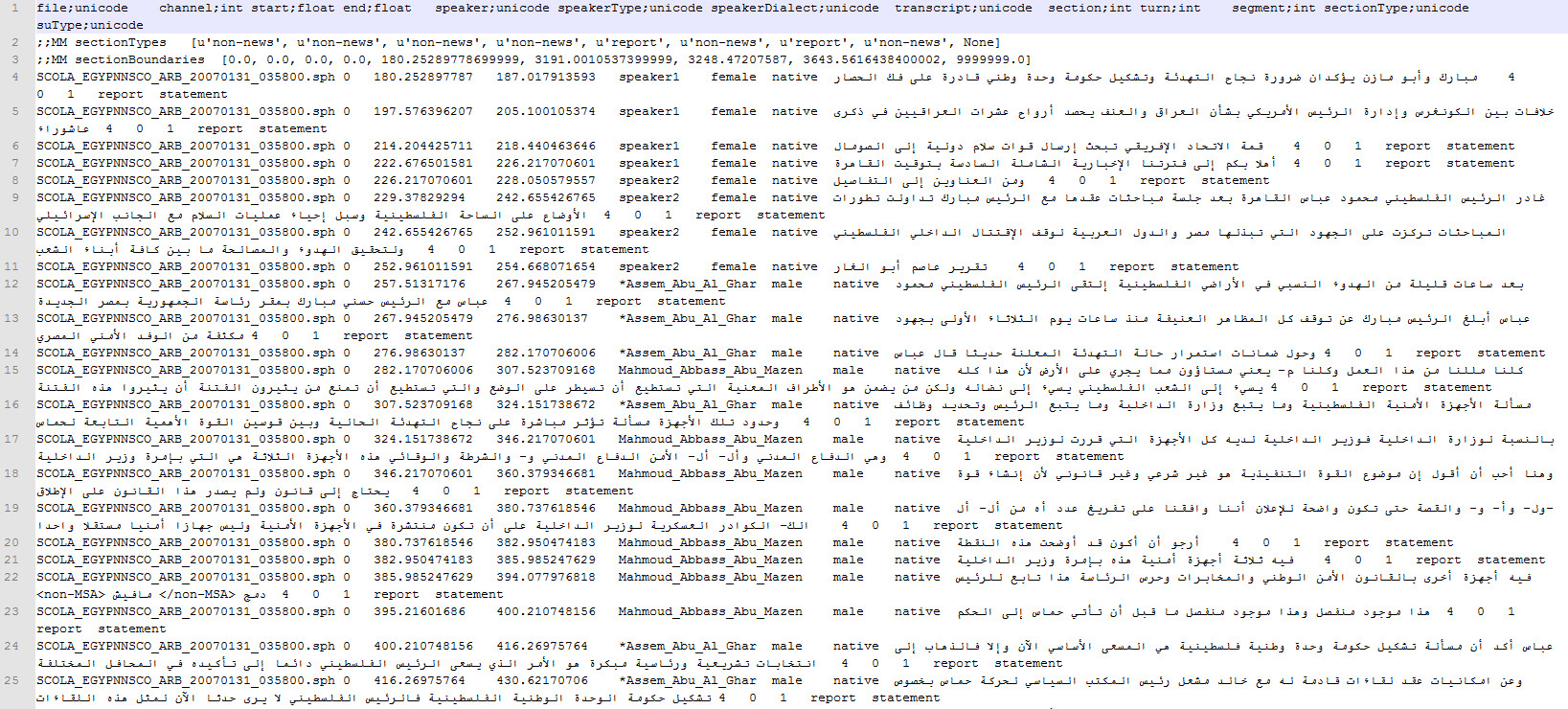
The transcript file is a tab-delimited file containing a row for each utterance (also called a segment in the LDC transcription terminology). Each row contains the corresponding transcription, accompanied by some additional information (e.g: the start and end time of the utterance in the audio file, the speaker’s name and gender, etc.) Some of this information is essential for the speech recognition process, some is helpful but not required, and some is application specific and not required at all for the training process. The transcription files also include information about which parts of the audio file contain news, which parts contain conversations, which parts contain reports, and which contain none.
As can be seen in Figure 1, the text of the transcripts is in Arabic, which means we will have to perform transliteration. The best choice would be the Buckwalter transliteration system, which was used by the MGB challenge organizers.
Preprocessing
Dealing with data that is not straight MSA speech can be tricky. Non-Arabic utterances can be completely removed. However, utterances which include non-MSA parts need experimentation to conclude whether using them or removing them is the right choice. Segments marked as “Non-news” can include commercials, which means they might contain music or noise. This will also need experimentation, and may benefit from music-speech separation.
Conclusion
In this post, we discussed the GALE Phase 2 Arabic Broadcast Conversation corpus (speech and transcripts), and we examined how the transcripts are organized.
In the following post, I’ll detail the steps I will follow for preprocessing the transcripts.