A Brief History of ASR: Automatic Speech Recognition
This moment has been a long time coming. The technology behind speech recognition has been in development for over half a century, going through several periods of intense promise — and disappointment. So what changed to make ASR viable in commercial applications? And what exactly could these systems accomplish, long before any of us had heard of Siri?
The story of speech recognition is as much about the application of different approaches as the development of raw technology, though the two are inextricably linked. Over a period of decades, researchers would conceive of myriad ways to dissect language: by sounds, by structure — and with statistics.
Early Days
Human interest in recognizing and synthesizing speech dates back hundreds of years (at least!) — but it wasn’t until the mid-20th century that our forebears built something recognizable as ASR.
 1961 — IBM Shoebox
1961 — IBM Shoebox
Among the earliest projects was a “digit recognizer” called Audrey, created by researchers at Bell Laboratories in 1952. Audrey could recognize spoken numerical digits by looking for audio fingerprints called formants — the distilled essences of sounds.
In the 1960s, IBM developed Shoebox — a system that could recognize digits and arithmetic commands like “plus” and “total”. Better yet, Shoebox could pass the math problem to an adding machine, which would calculate and print the answer.
Meanwhile researchers in Japan built hardware that could recognize the constituent parts of speech like vowels; other systems could evaluate the structure of speech to figure out where a word might end. And a team at University College in England could recognize 4 vowels and 9 consonants by analyzing phonemes, the discrete sounds of a language.
But while the field was taking incremental steps forward, it wasn’t necessarily clear where the path was heading. And then: disaster.
 October 1969 — The Journal of the Acoustical Society of America
October 1969 — The Journal of the Acoustical Society of America
A Piercing Freeze
The turning point came in the form of a letter written by John R. Pierce in 1969. Pierce had long since established himself as an engineer of international renown; among other achievements he coined the word transistor (now ubiquitous in engineering) and helped launch Echo I, the first-ever communications satellite. By 1969 he was an executive at Bell Labs, which had invested extensively in the development of speech recognition.
In an open letter published in The Journal of the Acoustical Society of America, Pierce laid out his concerns. Citing a “lush” funding environment in the aftermath of World War II and Sputnik, and the lack of accountability thereof, Pierce admonished the field for its lack of scientific rigor, asserting that there was too much wild experimentation going on:
“We all believe that a science of speech is possible, despite the scarcity in the field of people who behave like scientists and of results that look like science.” — J.R. Pierce, 1969
Pierce put his employer’s money where his mouth was: he defunded Bell’s ASR programs, which wouldn’t be reinstated until after he resigned in 1971.
Progress Continues
Thankfully there was more optimism elsewhere. In the early 1970s, the U.S. Department of Defense’s ARPA (the agency now known as DARPA) funded a five-year program called Speech Understanding Research. This led to the creation of several new ASR systems, the most successful of which was Carnegie Mellon University’s Harpy, which could recognize just over 1000 words by 1976.
Meanwhile efforts from IBM and AT&T’s Bell Laboratories pushed the technology toward possible commercial applications. IBM prioritized speech transcription in the context of office correspondence, and Bell was concerned with ‘command and control’ scenarios: the precursors to the voice dialing and automated phone trees we know today.
Despite this progress, by the end of the 1970s ASR was still a long ways from being viable for anything but highly-specific use-cases.
 This hurts my head, too.
This hurts my head, too.
The ‘80s: Markovs and More
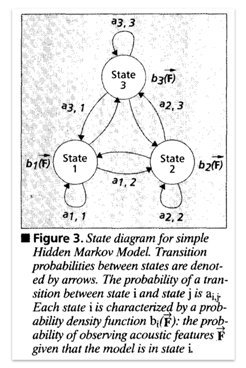
A key turning point came with the popularization of Hidden Markov Models(HMMs) in the mid-1980s. This approach represented a significant shift “from simple pattern recognition methods, based on templates and a spectral distance measure, to a statistical method for speech processing”—which translated to a leap forward in accuracy.
A large part of the improvement in speech recognition systems since the late 1960s is due to the power of this statistical approach, coupled with the advances in computer technology necessary to implement HMMs.
HMMs took the industry by storm — but they were no overnight success. Jim Baker first applied them to speech recognition in the early 1970s at CMU, and the models themselves had been described by Leonard E. Baum in the ‘60s. It wasn’t until 1980, when Jack Ferguson gave a set of illuminating lectures at the Institute for Defense Analyses, that the technique began to disseminate more widely.
The success of HMMs validated the work of Frederick Jelinek at IBM’s Watson Research Center, who since the early 1970s had advocated for the use of statistical models to interpret speech, rather than trying to get computers to mimic the way humans digest language: through meaning, syntax, and grammar (a common approach at the time). As Jelinek later put it: “Airplanes don’t flap their wings.”
These data-driven approaches also facilitated progress that had as much to do with industry collaboration and accountability as individual eureka moments. With the increasing popularity of statistical models, the ASR field began coalescing around a suite of tests that would provide a standardized benchmark to compare to. This was further encouraged by the release of shared data sets: large corpuses of data that researchers could use to train and test their models on.
In other words: finally, there was an (imperfect) way to measure and compare success.
 November 1990, Infoworld
November 1990, Infoworld
Consumer Availability — The ‘90s
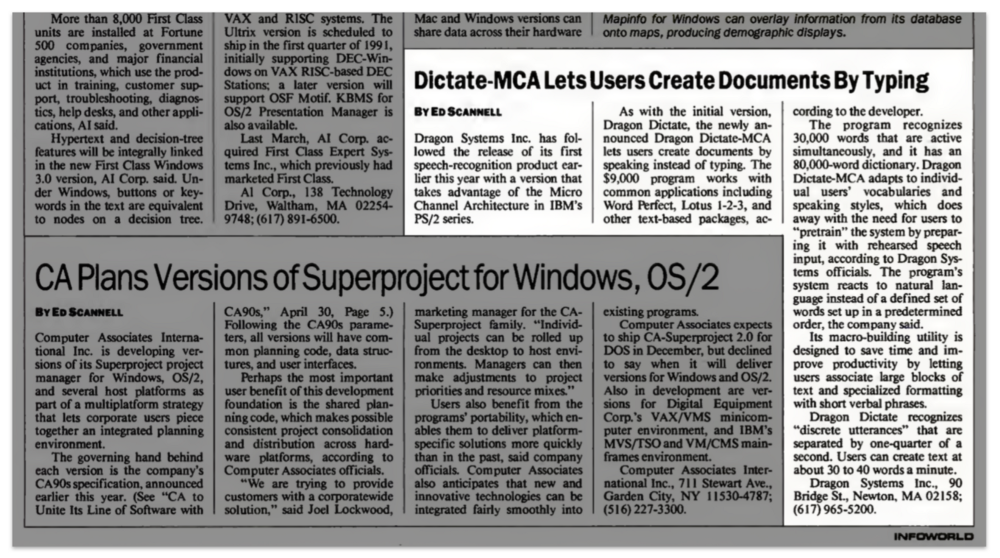
For better and worse, the 90s introduced consumers to automatic speech recognition in a form we’d recognize today. Dragon Dictate launched in 1990 for a staggering $9,000, touting a dictionary of 80,000 words and features like natural language processing (see the Infoworld article above).
These tools were time-consuming (the article claims otherwise, but Dragon became known for prompting users to ‘train’ the dictation software to their own voice). And it required that users speak in a stilted manner: Dragon could initially recognize only 30–40 words a minute; people typically talk around four times faster than that.
But it worked well enough for Dragon to grow into a business with hundreds of employees, and customers spanning healthcare, law, and more. By 1997 the company introduced Dragon NaturallySpeaking, which could capture words at a more fluid pace — and, at $150, a much lower price-tag.
Even so, there may have been as many grumbles as squeals of delight: to the degree that there is consumer skepticism around ASR today, some of the credit should go to the over-enthusiastic marketing of these early products. But without the efforts of industry pioneers James and Janet Baker (who founded Dragon Systems in 1982), the productization of ASR may have taken much longer.
 November 1993, IEEE Communications Magazine
November 1993, IEEE Communications Magazine
Whither Speech Recognition— The Sequel
25 years after J.R. Pierce’s paper was published, the IEEE published a follow-up titled Whither Speech Recognition: the Next 25 Years, authored by two senior employees of Bell Laboratories (the same institution where Pierce worked).
The latter article surveys the state of the industry circa 1993, when the paper was published — and serves as a sort of rebuttal to the pessimism of the original. Among its takeaways:
-
The key issue with Pierce’s letter was his assumption that in order for speech recognition to become useful, computers would need to comprehend what words mean. Given the technology of the time, this was completely infeasible.
-
In a sense, Pierce was right: by 1993 computers had meager understanding of language—and in 2018, they’re still notoriously bad at discerning meaning.
-
Pierce’s mistake lay in his failure to anticipate the myriad ways speech recognition can be useful, even when the computer doesn’t know what the words actually mean.
The Whither sequel ends with a prognosis, forecasting where ASR would head in the years after 1993. The section is couched in cheeky hedges (“We confidently predict that at least one of these eight predictions will turn out to have been incorrect”) — but it’s intriguing all the same. Among their eight predictions:
-
“By the year 2000, more people will get remote information via voice dialogues than by typing commands on computer keyboards to access remote databases.”
-
“People will learn to modify their speech habits to use speech recognition devices, just as they have changed their speaking behavior to leave messages on answering machines. Even though they will learn how to use this technology, people will always complain about speech recognizers.”
The Dark Horse
In a forthcoming installment in this series, we’ll be exploring more recent developments and the current state of automatic speech recognition. Spoiler alert: neural networks have played a starring role.
But neural networks are actually as old as most of the approaches described here — they were introduced in the 1950s! It wasn’t until the computational power of the modern era (along with much larger data sets) that they changed the landscape.
But we’re getting ahead of ourselves. Stay tuned for our next post on Automatic Speech Recognition by following Descript on Medium, Twitter, or Facebook.
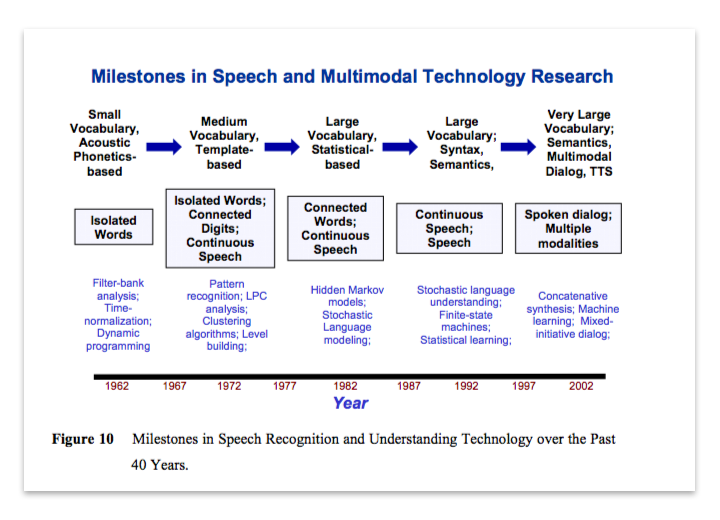 Timeline via Juang & Rabiner
Timeline via Juang & Rabiner